Custom AI Chatbot – Training ChatGPT (LLMs) On Your Own Data
Custom AI Chatbot – Training ChatGPT (LLMs) On Your Own Data
GPT-4 by Open AI is an extremely powerful language model and its potential extends far beyond the capabilities discussed in our earlier blog post about how businesses can use ChatGPT and its real-world applications. While businesses have embraced ChatGPT for various tasks and we’ve seen the rise of overnight “prompt prodigy’s”, training GPT-4 on your own data presents unique challenges and complexities that must be navigated. In this post, we will delve deeper into the details involved in training GPT-4 with custom datasets and explore the considerations businesses need to address to harness the full potential of this cutting-edge technology.
By using your own data sets to train GPT-4 or any other language model for that matter businesses can unlock new opportunities for innovation and leverage the model’s capabilities to gain valuable insights, streamline operations, and deliver enhanced user experiences.
7 examples of how you can use your own data to train GPT-4
Customer Support: Train your bot on customer support conversations, allowing it to provide automated responses and assist customers in real-time. You can upload or link to existing knowledge base which can be used to train your bot.
Legal Research: Use legal documents and case files to train, enabling it to assist with legal research, draft legal documents, or provide insights on specific cases.
Tailored News Aggregator: Train GPT-4 on your preferred news sources and topics of interest, allowing it to curate personal news summaries or recommend relevant articles.
Financial Analysis: Train your agent on financial data, market trends, and economic indicators to assist with investment analysis, predict market movements, or provide personal financial advice.
Social Media Monitoring: Use social media data to train GPT-4, enabling it to monitor online conversations, identify trends, and provide sentiment analysis or brand monitoring services.
Virtual Assistant: Train GPT-4 on your personal preferences, dietary plans, schedules, and tasks, allowing it to act as a virtual assistant to manage appointments, provide reminders, and offer suggestions.
Product Recommendation: Train GPT-4 on customer purchase history and product reviews, allowing it to provide personalised recommendations based on individual preferences and past interactions.
These are just illustrative examples, it’s important to remember that training GPT-4 or any other language model with your own data requires careful consideration of data privacy, ethics, and legal compliance.
Combining External Data With Large Language Models (LLMs)
OpenAI is rolling out updates at warp speed but currently AI developers must use frameworks such as LangChain, Lllama, Haystack and Hugging Face to combine Large Language Models (LLMs) like GPT-4 with external data, these frameworks also allow you to have greater control over prompts and if done right can be more cost effective.
Understanding The Importance Of LangChain
LangChain offers a unified interface that caters to various use cases. Suppose you have already built a custom workflow and now desire a similar one but with a Large Language Model (LLM) from Hugging Face instead of OpenAI. With LangChain, making this transition is as straightforward as adjusting a few variables. Additionally, LangChain has begun wrapping API endpoints with LLM interfaces. This exciting development enables you to communicate instructions to websites or online applications using plain English, simplifying the interaction process. Simply put, LangChain provides a versatile solution for seamless integration and effortless communication with LLMs, regardless of the specific use case or LLM provider.
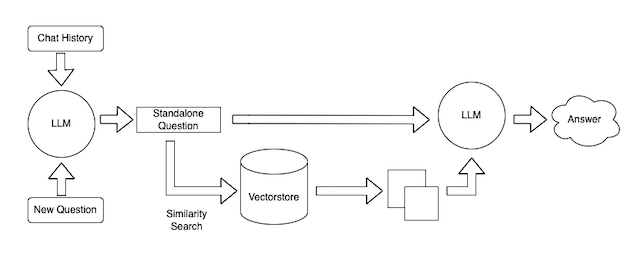
Looking to install LangChain, I would recommend you first read their quick start guide.
Need help designing and creating your custom chatbot? Chat with us.



